こんにちは、サクです。
今回はPythonを使ってWebスクレイピングを行ってみたいと思います。
文系だからプログラミングなんて分からない、そんな皆さんにも簡単に体感できる方法をお伝えします。
私もプログラミング未経験者で絶賛勉強中ですので、復習を兼ねて記事を書いております(^^;)
Webスクレイピングとは
そもそもWebスクレイピングとは何のことでしょうか。
Webスクレイピングとは、指定したWEBサイトから情報収集したうえで、利用しやすく加工することです。
こらからはマーケティングは、WEBサイトを意識して行うことは必須となります。顧客理解を進めるうえで、どのようなサイトが人気があるか等を知るために、Webスクレイピングの知識があると大きな武器になると考えられます。
スクレイピングが禁止されているWebサイトがあるので注意しましょう。
環境構築
プログラミング初心者が最初に躓きやすいところが環境構築です。
そこから上手くいかなくて、いやになるなんてことは、結構あるあるです(^^;)
そこで難しい環境構築が不要なGoogle Colaboratory(グーグルコラボラトリー)を使います。
Googleアカウントがあれば超簡単。
まずGoogleアプリからGoogleドライブを起動します。
そして「新規作成」を押下し、「その他」をマウスをホバーすると、「Google Colaboratory」が表示されますのでクリックします。
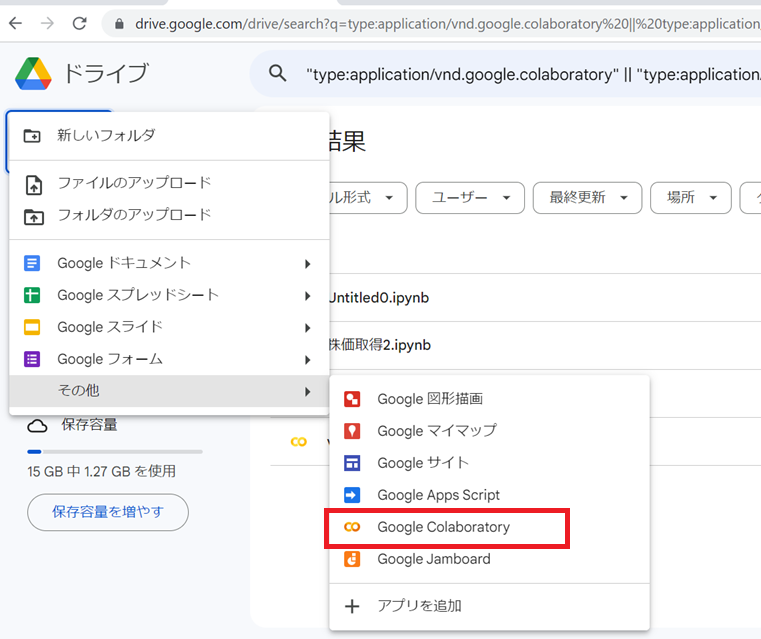
すると、下記の画面が表示されます。
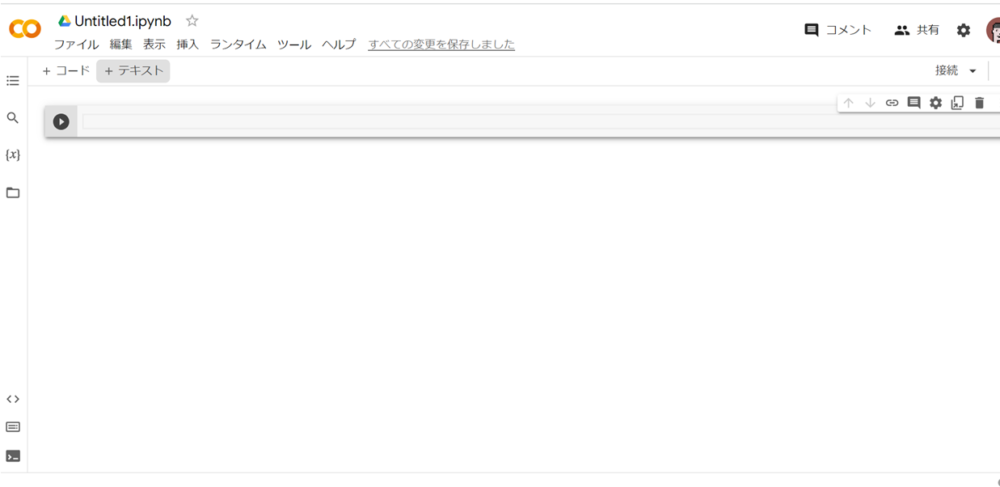
黒丸の三角のマークがついた枠(セルといいます)が表示されますので、そこにプログラムを記載していきます。
めちゃ簡単ですよね。
プログラムを記載したら「Shift + Enter」で次のセルが表示されて記載していきます。
具体的なプログラミング
今回は自分のブログ記事のh2タグ(小見出し)を抜きだすプログラムを作成します。
※今回はJavaScriptで作られていないホームページに利用できます。
※初めての方は環境構築のために「! conda install beautifulsoup4-y」とコマンドを打って実行します。

まずは「BeatifulSoup」というライブラリと「requests」というライブラリをインポートします。
こられはスクレイピングに必要なプログラムのセットとなります。
今の時点では、とりあえず必要なおまじないと思ってください。

そして、今回スクレイピングをする記事のURLをダブルコーテーションで囲います。
そして「url」とい変数に代入します。

そして、このURLの情報を取得するために、requestsを使います。
getというメソッドを使い、カッコのなかに先ほどのurl変数を入れると、サイトから情報を取得できます。
その情報を「r」という変数に代入します。

そして情報をBeatifuSoupで分析します。そのためには上記のように記載して、「soup」という変数に代入。

soupから必要な「h2タグ」の情報を取り出します。
すると青枠で囲ったように、h2タグ情報が取得されました。

しかしこのままだと何が何だかわかりませんよね(^^;)
そこでこの中からテキスト情報を取り出します。

上記は、リストと呼ばれるデータをまとめた箱のようなものに入っています。
そこからfor分と使ってテキストを抜き出すループ(繰り返し処理)を行います。
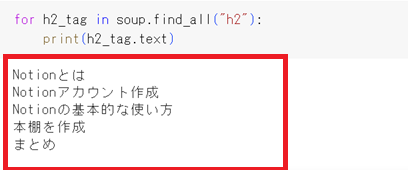
結果、赤枠で表示したようなh2(小見出し)を抽出することに成功しました!
まとめ
実際にはHTMLの基本知識は必要となりますが、数行のプログラムで実行できました。
・RequestsでHTMLを取得する
・取得したHTMLをBeatifuSoupで分析する
・自分の欲しい情報を抽出する
一度触ってみて、実体験すると興味も湧いて学習意欲も高まります。
まだ私も初心者ですので、一緒に精進していきましょう。
以上、サクでした。
